
Lagom without clustering
There is a broad spectrum of reactive systems and maintaining an applicative cluster, inside each and every service, is probably on one end of this spectrum. Beware that Lagom’s default persistence mecanism is using Akka Cluster and you better know what you are doing before putting it in production.
In this article I will provide an alternative to organization willing to deploy Lagom application with CQRS/ES but without having to manage a cluster on a dynamic containerized environment.
Disclaimer: This alternative is only compatible with Persistent Entities in a Relational Database.
Introduction
According to the Manifesto, reactive systems are Responsive, Resilient, Elastic and Message Driven. Systems built as Reactive Systems are more flexible, loosely-coupled and scalable. They are significantly more tolerant of failure and when failure does occur they meet it with elegance rather than disaster.
According to the Lightbend, Lagom helps you build such reactive systems. To do so, it relies on Akka, Play and a Container Orchestrator. The default pattern for persisting entities takes advantage of Event Sourcing (ES) with Command Query Responsibility Segregation (CQRS). Lagom heavily relies on Akka Persistence, Akka Singleton and therefor on Akka Cluster to handle this distributed persistent pattern.
I will argue that, in most case, a cluster is not required to handle CQRS/ES and will demonstrate how we can use Akka Persistence without having to create a cluster containing every instance of a service. Moreover, in a classical setup, achieving the same level of responsiveness and resilience is surprisingly hard when switching from a Play to a Lagom application. Go to the last section if you want to learn why.
How to run Lagom in production without Akka Cluster ?
Cluster Singleton are critical to Lagom’s architecture, they are used by read-sides and persistent entities. Indeed, for some use cases it is mandatory to ensure that you have exactly one actor of a certain type running somewhere in the cluster. Lagom needs this property to ensure that read-sides will treat each event exactly once. Persistent entities use singletons to ensure that, for a single entity, two events can’t be persisted with the same sequence id, this is also a convenient way to create a distributed cache.
We can use both our container orchestrator and a relational database to enforce those garanties without relying on an applicative cluster. I modified the activator-lagom-java-chirper-jdbc example to show you how we can start a multi-instance Lagom service inside a docker-compose without Akka Cluster. This code is available here.
Configuration
As chirp-impl is the only service using Relational Database Persistent Entities, it’s the only service we will configure to run without applicative cluster all other services will only have one instance. First, we need to make sure chirp-impl, friend-impl, activity-stream-impl and load-test-impl are ready to run in containers, in production mode.
We add the environment variable to set up play.http.secret.key, we set up lagom.cluster.exit-jvm-when-system-terminated, modified the logback.xml files and added external service adresses configuration via environment variables.
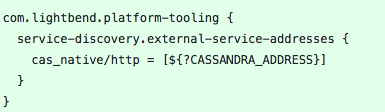
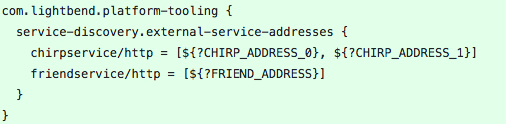
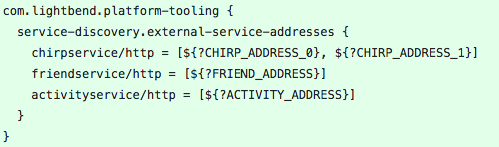
Now, let’s focus on chirp-impl/src/main/resources/application.conf.
We need a way to add roles to each instance of chirp and to remove the state of the ShardCoordinator from the database.

Last, we need to be able to decrease the passivation timeout of persistence entities and to enforce that read side will only run on specific roles.
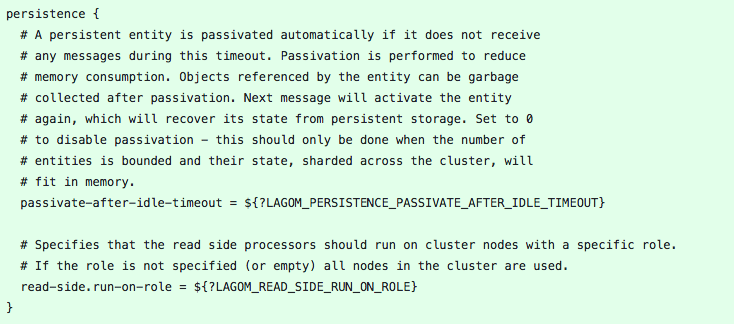
Using those variables, we can create a docker-compose.yml that will start two instances of chirp. Singletons will run on chirp-impl-singleton, we rely on docker restart strategy and lagom.cluster.exit-jvm-when-system-terminated=on to make sure that the singletons will always run if docker is started.
Regarding the entities, we set the passivation timeout at 1ms on chirp-impl-singleton and 30s on chirp-impl-service, this configuration will allow us to expose the consistency enforced by postgresql. In production, you should set all passivation timeout at 1ms.
Passivation
As the state of the entities are persistent you may stop entities that are not used to reduce memory consumption and enforce a state recovery from the database on the next message. To support graceful passivation without losing such messages the entity actor can send ShardRegion.Passivate to its parent Shard. The specified wrapped message in Passivate will be sent back to the entity, which is then supposed to stop itself. Incoming messages will be buffered by the Shard between reception of Passivate and termination of the entity. Such buffered messages are thereafter delivered to a new incarnation of the entity.
Eventually Consistence and Persist Exception
This configuration means that two successive read only commands on the same instance will have a 1 millisecond eventually consistency on chirp-impl-singleton and a 30 second consistency on chirp-impl-service.
Examples : The following scenario will be eventually consistent if the three following steps are performed in the same millisecond.
- A command on chirp-impl-singleton load entity A state 4 from database.
- A write command on chirp-impl-service change entity A state from 4 to 5.
- A read only command on chirp-impl-singleton might return in memory entity A state 4.
The following scenario will be eventually consistent if the three following steps are performed in a 30 seconds interval.
- A command on chirp-impl-service load entity A state 4 from database.
- A write command on chirp-impl-singleton change entity A state from 4 to 5.
- A read only command on chirp-impl-service might return in memory entity A state 4.
It also means that the following scenario will fail if the three following steps are performed in a 30 seconds interval.
- A command on chirp-impl-service load entity A state 5 from database.
- A write command on chirp-impl-singleton change entity A state from 5 to 6.
- A write command on chirp-impl-service change entity A state from 5 to 6 and the insertion in the journal fails with a PersistentEntity.PersistException.
Here, a simple retry will be needed.
ERROR: duplicate key value violates unique constraint "journal_pk"
DETAIL: Key (persistence_id, sequence_number)=(ChirpTimelineEntity1234232, 16) already exists.
STATEMENT: insert into "journal" ("deleted","persistence_id","sequence_number","message","tags") values ($1,$2,$3,$4,$5)
[error] chirpservice - Exception in PathCallId{pathPattern='/api/chirps/live/:userId'}
com.lightbend.lagom.javadsl.persistence.PersistentEntity$PersistException: Persist of [akka.persistence.journal.Tagged] failed in [sample.chirper.chirp.impl.ChirpTimelineEntity] with id [1234232],
caused by: {ERROR: duplicate key value violates unique constraint "journal_pk"
Detail: Key (persistence_id, sequence_number)=(ChirpTimelineEntity1234232, 16) already exists.
[error] c.l.l.i.j.p.PersistentEntityActor - Failed to persist event type [akka.persistence.journal.Tagged] with sequence number [16] for persistenceId [ChirpTimelineEntity1234232].
org.postgresql.util.PSQLException: ERROR: duplicate key value violates unique constraint "journal_pk"
Detail: Key (persistence_id, sequence_number)=(ChirpTimelineEntity1234232, 16) already exists.
at org.postgresql.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2455)
at org.postgresql.core.v3.QueryExecutorImpl.processResults(QueryExecutorImpl.java:2155)
at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:288)
at org.postgresql.jdbc.PgStatement.executeInternal(PgStatement.java:430)
at org.postgresql.jdbc.PgStatement.execute(PgStatement.java:356)
at org.postgresql.jdbc.PgPreparedStatement.executeWithFlags(PgPreparedStatement.java:168)
at org.postgresql.jdbc.PgPreparedStatement.executeUpdate(PgPreparedStatement.java:135)
at com.zaxxer.hikari.pool.ProxyPreparedStatement.executeUpdate(ProxyPreparedStatement.java:61)
at com.zaxxer.hikari.pool.HikariProxyPreparedStatement.executeUpdate(HikariProxyPreparedStatement.java)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) # Conclusion
Lagom with Akka Cluster is the best way to run a Reactive Systems in production, at scale. When scale is not a challenge, we can make configuration modifications to run Lagom without cluster with few steps back (eventually consistence on read only command and higher rate of persist exception).
Bonus: Why keeping an Akka Cluster up and running is tedious
There is multiple critical steps in an Akka Cluster lifecycle. One miss configuration will lead to request timeout or duplicated of job. Please have a look at Akka Management documentation before reading this part. If you are using Kubernetes, a lot of work was put in Lightbend Orchestration for Kubernetes to simplify deployment.
Let’s say we need to deploy a cluster with 3 nodes (a Lagom service with 3 instances).
Service Discovery
In a dynamic containerized environment, you have two choices, either you use the load balancer in front of your instances or you rely on your orchestrator Api.
The first solution means that you need a way to expose the akka-management endpoint of an instance without exposing the service endpoint of the instance, failing to do so will result in traffic being routed to an instance that did not joined the cluster. To my knowledge, this is not possible in mainstream orchestrators except Kubernetes (see publishNotReadyAddresses).
Be careful, the DNS SRV client will fail to handle truncate response with TCP fallback and this will blow in your face if the number of instances in the truncated response is less than contact-point-discovery.required-contact-point-nr required by the bootstrap process.
The second (recommended) solution is to heavily couple your service with your orchestration mecanism. You better call your infra team and it will be easier if you run on Kubernetes.
Cluster Bootstrap
Congratulation, you managed to list all the ip:port of the deployed instances of your service. If you are lucky, you did so without exposing the instance service endpoint behind your load balancer.
Let’s set contact-point-discovery.required-contact-point-nr = 2 such that it is more than half the number of desired instances.
In the case no cluster exists yet – the initial bootstrap of a cluster – nodes will keep probing one another for a while (see akka.management.cluster.bootstrap.contact-point-discovery.stable-margin) and once that time margin passes, they will decide that no cluster exists, and one of the seen nodes should join itself to become the first node of a new cluster.
This basically means that you should expect at least a ~5 seconds down time if you lost all your instances after the orchestrator managed to redeploy 2 instances and the service discovery mecanism did its job (see akka.management.cluster.boostrap.interval).
In the case a cluster already exists, reaching other nodes should be easy, if you manage to configure the akka.remote.netty.tcp hostnames and ports.
If the bootstrap failed, the instance might be in zombie mode, don’t forget to set lagom.cluster.exit-jvm-when-system-terminated = on.
Cluster Joining and Leaving
The joining mecanism is straighforward.
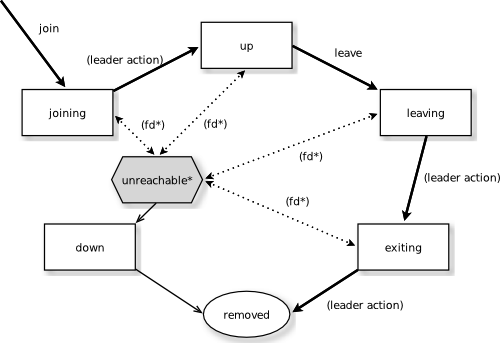
Notice that if an instance is marked as unreachable (because it was on a failing server or was shutdown by the orchestrator without timeout), the cluster will have to down the unreachable instance before accepting the joining one.
Don’t forget to set akka.cluster.shutdown-after-unsuccessful-join-seed-nodes.
If you are on Kubernetes, don’t forget to switch the readiness to true after joining. If you are on an other orchestrator, during the time between the liveness was set to true and the time you joined the cluster, you were probably failing to serve client resulting in degraded responsiveness.
Split Brain Resolver or Downing provider
From the cluster to transitioned an instance from unreachable to down, you have to provide a Split Brain Resolver that will handle network partition and machine crashes. This is a fundamental (and really hard) problem in distributed systems.
Most open sourced Split Brain Resolvers have edge cases that can bring down your entire cluster resolving in instabilities. We recommend using akka-cluster-custom-downing.
Managing liveness and readiness inside your orchestrator
On top of all those considerations, you will have to make sure your Akka Cluster configuration is compatible with the liveness and readiness processes (number of instances deployed in same time, rolling update starting by the newest instance, canary mode, etc…). The bootstrap will also be sensible to DNS misconfigurations and Docker registry latency.